


The Illusion of Thinking Apple Researchers
Never attribute to malice that which is adequately explained by stupidity.

Apple’s new AI paper “The Illusion of thinking” is spreading like wildfire in the online AI world, where recently converted Crypto bros “give expert insight” aka regurgitate every bit of hype laden marketing dross that crosses their feed.

Apple’s new paper is aptly named not because it proves anything but because either the researchers themselves vibe coded their way to a publication without understanding what they are researching or they relied on the collective unthinking race to be first to break big news online and get all of the clicks, to bypass sanity checks. Unfortunately it seems like the researchers themselves are bad actors, given far too much of a platform by Apple.
The paper is an interesting exploration into the reasoning limitations of some of the current models, with a terrible title and conclusions that are designed to steal headlines rather than worry about thorny issues like veracity. The paper fails to cite that it is ostensibly exploring the well known issue of task coherence in LLMs and that model developers at OpenAI and Anthropic are openly saying that multi-turn reasoning and long running task completion are still in their infancy, as far as exploration of their limitations and a big limiting factor is quality data, which they are racing to address.
In this context it’s like saying we’ve measured the maximum duration of the Wright brother’s first plane and it can’t fly for very long therefore: “BREAKING NEWS: Planes can’t fly and never will!”
These same Apple researchers 7 months ago released a paper I debunked saying that LLMs can’t reason. It followed the same pattern of some interesting experiments combined with overblown conclusions. This new paper at least shows them retreating from their previous stance of “LLMs can’t reason” to “LLMs can’t reason beyond a specific complexity breakpoint and probably never will.” Looking at the delta in stance between the papers, it’s nice to see we have the trolls on the run!
Getting into more technical detail about the paper’s claims:
Given that adding more reasoning tokens doesn’t further help the models, they draw the conclusion that this is showing a fundamental reasoning limit for LLMs.
They ignore that models are not calculators, they have implicit reasoning error rates and each step is a chance to add more error, during training it likely learns that if it’s a problem that requires a lot of steps, it’s probably more likely to get the answer right if it just guesses the answer. For o3-mini-high(one of the models discussed in the paper) on our reasoning test it scored 75%, this means after 10 such reasoning steps it would only have a 6% chance of being right. If it just tries to do it’s best guess, it avoids the compounding error.
Also if they use a training regime similar to Deepseek, the KL part of the reward will favour brevity, which will create a downward pressure favouring correct guesses, rather than full reasoned answers.
Other papers such as Scaling Reasoning can Improve Factuality in Large Language Models have already shown that if they add extra training via fine tuning to change how the model thinks and responds, not simply just changing the number of reasoning tokens on an API call, it does indeed scale the reasoning capability for a given LLM. Quality researchers should have been able to understand the existing literature, identify that it was conducted with a more rigorous approach and not drawn such conclusions.
It would be interesting if they plotted where the depth of reasoning cutoff appears plotted against the intrinsic reasoning ability of a wide array of models. This leads nicely to the next point.In their last paper they cherry picked models that helped make their point and here they’ve done it again. o3, o3-high, o4-mini-high and Deep Research are all missing. They’ve been released for several months now, why choose o3-mini-high?
Do the newer models have different cutoffs that align with their reasoning capability? Seems like something you might want to test before making bold statements to the world about fundamental limitations of LLMs.
Or you know, at least checking if such results already exist before publishing:
They use incredibly well known puzzles, then having run them with the algorithm in the prompt and not in the prompt and seeing no real difference in the results, they try to draw the conclusion that since showing the LLM the way to solve it didn’t help, the LLM is not thinking.
This is baffling to me. The LLM obviously knew how to do the puzzle even without the algorithm, so why would it make any difference? It just can’t do lots of steps in a row without making an error somewhere. This is the same if you have the algorithm or not.
Also if we gave the LLM access to Python and said run the algorithm, it would get the right answer every time. LLMs despite running on a computer, can’t without added tools like Python, execute algorithms perfectly. This is well known, most humans can’t do it well either. It doesn’t mean we can’t think.

The truth is we’re just in the infancy of exploring long chain reasoning and multi-turn reliable execution. Results on benchmarks like BrowseComp show that models not included in this research are getting better at long chains of reasoning and that additional reasoning tokens improve performance.
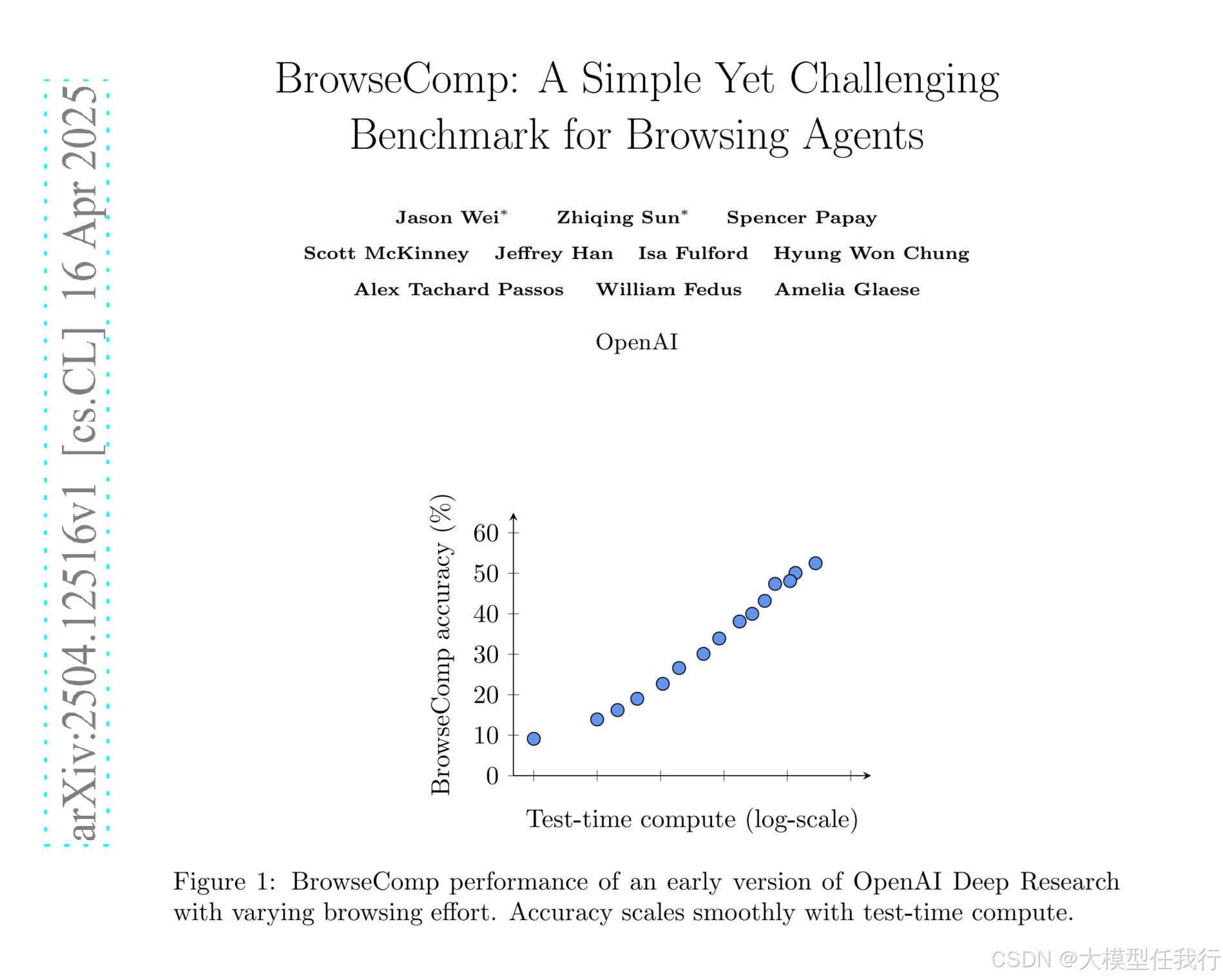
If we didn’t live in a hype driven social media free for all, the Apple researchers would be suitably recoiling in embarrassment and struggling to get speaking slots at conferences. Having released non peer review results with hyperbolic conclusions which are known to be wrong at the time of publishing. They should be retraining into new career paths, unfortunately I’m sure I’ll be slapping my forehead when their next instalment drops in a few months time.
In the meantime remember folks, don’t feed the trolls!
> with a terrible title and conclusions that are designed to steal headlines
I feel like 99.99999% of coverage of AI in general is described by this sentence.